Selecting the Database For My New Project
Published:

Now that I finally have a project in mind - a real project that will actually take me a while (and a nice pile of new learning) to execute - I have to make some choices about what to use and how. My project idea is an interface for structuring and organizing data in a way that will be useful to writers (in particular, fiction writers having to keep track of a bunch of moving parts in stories and setting). I have some passing familiarity with databases at this point, I've worked with them for things like a CMS system in the past - and of course had to deal with them regularly as an end user at my previous jobs. So: how do I select which database to use?
From a development standpoint I have next to no existing knowledge of the subject, except understanding that SQL is a pretty standard interface, but there's loads of back-end things that all use SQL, and for that matter a relational database may not even be the best option for what I'm doing. This blog post is a learn-with-me exercise as I explain what I learn and make a final decision about what tools and libraries to implement and learn for this aspect of my project.
Requirements
It makes sense to me that the first thing I have to do in this process is to define what my requirements are. This might evolve as I research options and learn more about what is already possible with existing tools, and what solutions others have already developed, but as a basic step, I know I need to have a clear idea of what I require from a database to know how to select a database.
The most basic abstract level of my planned software is a collection of data entries that will connect to other entries in a handful of ways. For example, character or location entries may have to connect both to other character or location entries in an organized way, and both would have to connect to event entries, which would need to be chronologically sortable. I don't anticipate a requirement for multiple users to be able to write to the same data entries at once, although I shouldn't completely discount the idea either as collaborative situations exist. Is there any potential benefit to having the data files human-readable, or is data that is machine-readable only equally acceptable?
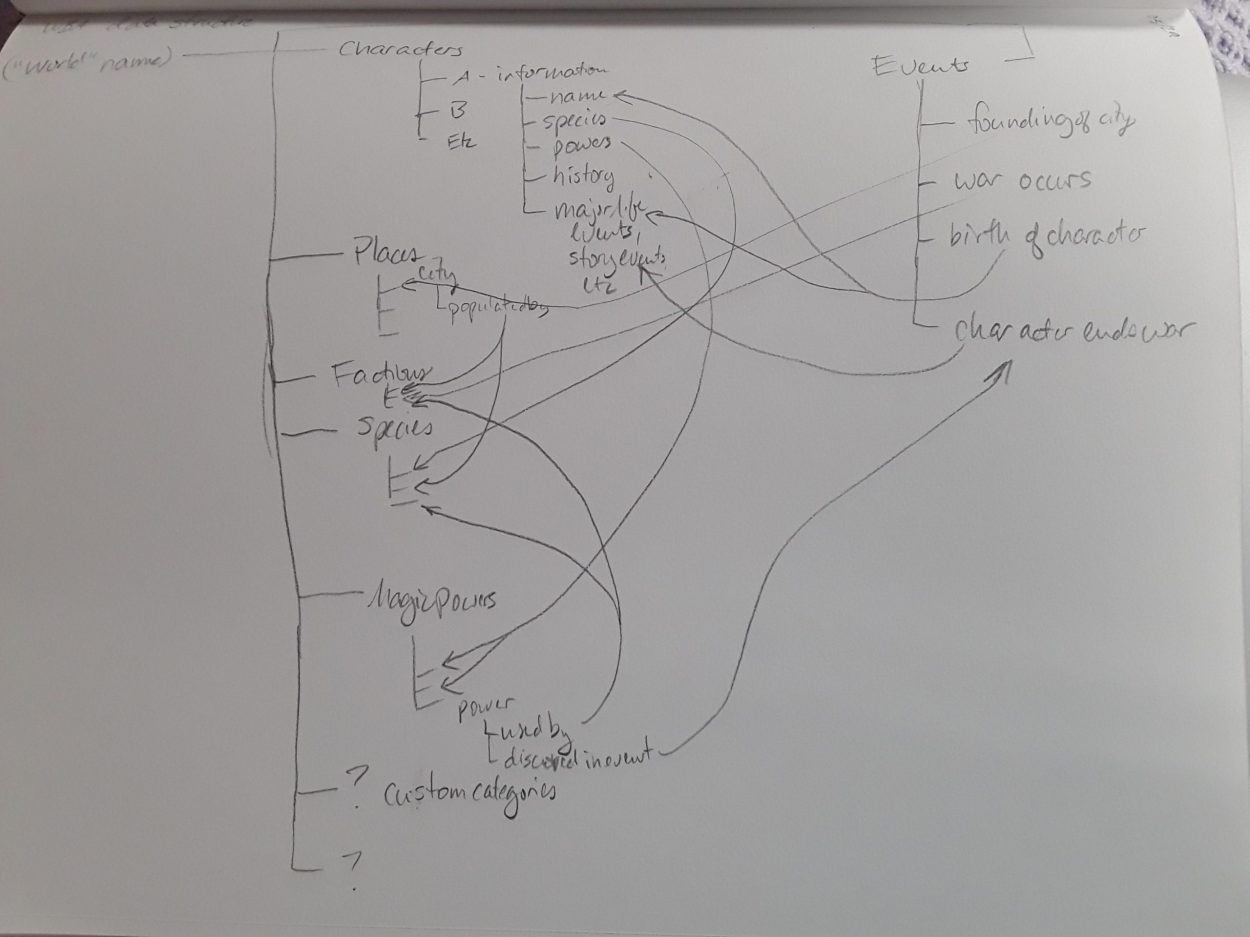
Also, because I'm working in Python, whatever I select needs to have a preexisting, robust library for interacting with Python to be worth my time at this stage in my learning.
Wiki?
I realized looking at my requirements that the functionality I desire is in many ways similar to the popular wiki format. I plan to do some things that a straight up wiki will not, and want the editing to be more seamless as the end user is also the content creator (I realize an argument could be made for the same on a public wiki but it is more often than not not the case.) So I don't think a wiki is an answer in and of itself, however there may be useful things I can take from wiki systems.
Structured vs Unstructured
I found an informative article on InfoQ about selecting a data storage solution which raised the question of structured vs unstructured data. It's an interesting question to consider. There are definitely parts of the data that should be structured (such as a character entry having a name and certain other attributes) and other parts of the data that would clearly not be structured (such as a written description of an event or location, or image files). I need a solution that can handle unstructured data, but provide some structure to live in (or else it's no better than a stack of handwritten notes ;) ).
Database options
My next step in analyzing which database selection would be optimal for my project is to try to get some handle on what my options actually are. As mentioned above, this is not something I'm very familiar with at this point. The following section goes into the options that I found enough readily available information on to be worth considering, and the major factors of each option.
SQL Options
Digital Ocean has a great overview of various open source SQL options, which I won't repeat in huge detail here. For my purposes, the biggest potential benefit of choosing an SQL option is that, as a common way to store data, it's a good thing to learn. Undoubtedly I will encounter SQL databases at different times and places in my software career, and it would be good to be familiar with them.
There are Python interfaces available for all of the SQL options I present here.
SQLite
SQLite is one of the leading contenders for an SQL based option. It's small, user friendly and portable, which would all benefit the single or minimally multi user experience I expect from my software. Limited concurrency isn't an issue for my use case. Multiple user groups is unlikely to be relevant, although preserving the functionality may allow greater flexibility later.
A single user local program (including mobile and game applications) appears to be the primary use case for SQLite, which matches my intentions. I don't anticipate the limited scale of SQLite databases to be a problem - 1TB of text data is huge, having that much to keep track of for one author would be...slightly absurd.
The only real drawback I see is the inefficiency of network based access, which could be a problem if cloud-based storage becomes an option worth including in the program at some point. I don't have an immediate plan for that, but internet accessible, location independent data for fiction writing would be more convenient for many people than keeping it all on one device.
MySQL
MySQL does lead in one important area: popularity and therefore documentation. Any information I need to find to set up my application the way I want should be fairly easy to find. That would also have the benefit of being a potentially relevant and useful skill for future projects I might contribute to.
A quick search on how to set it up, however, returns a downside: I'd need to install and run a MySQL database parallel to the application itself. Instead of my application controlling data directly, it would interact and connect with the data via a driver and server relationship. This seems like an unnecessary layer, an unnecessary place to potentially introduce errors in communication and complications. This would be useful if multiple clients or multiple programs were accessing the same database, but I don't anticipate that kind of situation occurring here.
MySQL also has some good security and backup options, but again, not necessary or useful for my application. It seems most useful for large scale operations, either with many users, multiple locations, web based delivery, or similar situations.
PostgreSQL
PostgreSQL seems to be the SQL server and interface of choice among many Python developers, which makes it the primary database selection candidate for my purpose of learning useful skills by doing. It does have the downside shared by MySQL, or most SQL options, in that I would have to run a PostgreSQL server as well as the application itself. I was initially put off by this, but further research indicates this is likely to be the case with almost any option I run, and by the end of the article I decided not to worry about it.
On first glance documentation seems significantly robust and tutorials plentiful. As an object-relational database, PostgreSQL has many features of object databases as well as meeting the SQL standards as a relational database. Maybe because of this, it also already supports many of Python's data types: another good bonus. It offers a chance to familiarize myself with an ORM such as Django's ORM or Flask's SQLAlchemy, which would have many more potential applications.
ACID compliance is unlikely to be an issue for my application but PostgreSQL has robust features to ensure data integrity, especially if concurrent writing does occur, which would leave the door open for multi-user operations. Sounds like it's not the easiest to back up, either, but the options are there, which is important.
PostgreSQL may be overkill for my application and next I'll look at no-SQL options, but given the above benefits, is the overall winner if I decide to go with an SQL based data storage option.
NoSQL Options
SQL has a lot of benefits but also comes with a lot of 'artificial' restraints, and a host of annoyances, as explained by Aphinya Dechalert on Medium. The way you interact with a SQL database is limited by the firmly ordered way in which the data structure is set up to begin with. This may be more confining than helpful for my needs. A more flexible approach where, should a user desire, almost anything can be configured in a custom way, would be more suitable. Additionally, running a separate server process to handle writing the data to storage seems like an unnecessary complication for the scale of my project.
Let's look at some data storage options that don't use SQL and see how they compare.
Data Models
It's worth noting at this point the four data models presented in the Medium article linked above. The "Key:value" model is too basic and simplistic for the kind of linked data I expect users to have. "Document" could work, with the right setup. "Column Family" also seems excessively simple, and not categorical enough on the whole. "Graph", however, seems like just the ticket: an interconnected web of data.
Note, of course, that none of these models are exclusive of one another; one could, for example, have a graph of collections of key:value pairs, or documents. However, anything that doesn't have some form of this capability won't meet my needs. The following are systems which can make use of a graph model, and play nicely with Python.
MongoDB
MongoDB's promotional video demonstrates how aggravatingly complicated it would be to access a traditional SQL database for the kind of richly linked environment I anticipate users having. However, it also seems a little short on linking features, itself, and looks better suited to situations in which you have one or more categories of unique entries with little or no crosslinking of information.
On the other hand, it's listed as a quite desirable database skill to have according to freeCodeCamp's review of Stack Overflow's 2020 Developer Survey. My overall assessment: it looks like it has the potential to be very useful, but I have reservations about document reference behavior. I could use it if I can successfully adapt the document structure to have the crosslinking behavior I want. For an example of a situation which I feel might cause issues: character A is involved in events 1, 2, and 3. Event 1 involves characters A, B, and C. The references need to go both ways from both of these situations; events 1, 2, and 3 cannot belong to character A any more than characters A, B, and C can belong to event 1. The nature of MongoDB's structure means this may be more complicated than it's worth to set up, especially since I anticipate a lot of this back-and-forth connection. (Tutorialspoint shows a way to do it manually, though, so MongoDB is still on the table as an option, given its other benefits.)
Neo4j
The definition of a graph database provided by Neo4j's documentation seems to be exactly what my project needs. The data stored is expected to be highly dependent on, and really mainly important because of, its connections to other data. The presentation of data will be significantly in terms of what it connects to. A graph database is therefore an extremely appealing selection. Honorable mention: OrientDB. OrientDB seems to have a pretty similar selection of features, and at a brief glance seems pretty similar. However, of the two, Neo4j is much more widely used, which means both a better chance of finding help if I need it and a better chance it will be useful for other future projects.
Non-Relevant Options
There are a ton of database options out there. I looked over a pretty significant portion of them making this decision. AWS's DynamoDB I considered briefly, but not looking for a managed service even if it is available in the free tier, and the data types and structures seem less than adequately flexible. Similarly Google's Bigtable and Firebase: I need something local, not a remote service. (And this definitely isn't going to be Big Data - probably only generated by one user per database, a few at the most!) I briefly considered Apache Cassandra and Redis but they don't seem, from a casual investigation, to be aimed at the right kinds of use cases. (In fact, for a broad overview of potentially relevant options, Kristof Kovacs has a great article discussing the major players and each of their main points.)
Final Debate
SQL vs Document Store
If I'm going to force a schema-less database to have a schema, why not use a schema database to begin with? Answer: if my data is not highly relational. The more research I do, the more it looks like the flexibility of a document-based DB would be a good choice. Customizing the quantity and type of available fields on an entry on the fly sounds like a good benefit. Some of the data would fit nicely in a table, but.... A lot of it won't, necessarily. And sometimes, the application might need user customizable data fields. A relational DB might have trouble with that, especially if the user wanted to change data fields after already entering a significant amount of their data. (Maybe they just realized an important way to classify characters in their world that doesn't have anything to do with typical groupings like factions, species, etc.)
One thing I would potentially lose by stepping away from SQL: Transactional editing, ACID, and so on. But they're not highly necessary for my use case. Data consistency is nice to have, but nobody's losing their lunch money if an operation doesn't complete just so; it's a record of creative thought, and the chances of the thought disappearing completely if the record fails are low. Frustrating, yes; devastating, no.
PostgreSQL Is likely to be more relevant to my probable future workflows, but MongoDB is more flexible and probably easier to make do what I want. Both are useful and desirable to learn, and probably good for me to be at least passingly familiar with both sooner or later. Learning PostgreSQL would be somewhat more manifold as it would familiarize me with SQL functionality, which would have a much broader range of applicability than MongoDB's unique query language. And while MySQL is also a completely valid option for a SQL DBMS, PostgreSQL has the benefit of a higher association with Python development, in general, and thus more likely to be relevant to any future work I do.
Ultimately, Sarah Mei's excellent explanation and visual representation of data schema has convinced me that MongoDB is not optimal for my needs. Repetition of data in relevant locations is extremely unappealing, and linking back and forth, sometimes cyclically, seems like a pretty inefficient way of handling the type of data relationships I anticipate.
SQL vs Graph DBMS
This still leaves the question of PostgreSQL vs, say, Neo4j. This is a tough one! The way I envision my data structure lends itself nicely to the native data structure of a graphDB. But the same relevancy questions arise. So, the next question is, can I make PostgreSQL behave similarly enough to a native graphDB to make it viable? Especially since I'm looking at contributing to an open source project who definitely would do better with a standard RDBMS, learning just one (if different aspects of it) would be a much more efficient use of my time.
After going back and forth on this question for days, I finally concluded that for a personal project like this there is not much risk in using the wrong thing. If I do my code carefully, the database interactions will be a completely separate layer from the function calls, so I can always change my mind later if the architecture doesn't work out for me. I was just about to pull the trigger, so to speak, on jumping into Neo4j....when I discovered Agensgraph.
There's some things that make me hesitate about Agensgraph, namely the support doesn't seem that great, and it's so new it doesn't have a wide user base at this point, so getting help may be a bit difficult. However, since it's based on PostgreSQL, it would dovetail nicely with learning PostgreSQL for other purposes, and still be able to use SQL to interact with it as needed. And again - there's very little risk to a bad choice here, at least at this stage, so, why not try it? I can always switch to Neo4j or straight up PostgreSQL later.
This research and decision took me days longer than I anticipated it would, but at least now I have a much better idea of the options and tools out there next time I have to decide on a database.
Next step: figure out how to install it and start interacting with the darn thing!
Update, a month later:
Using Agensgraph sounded like a great idea after all my research. Problem was, I couldn't get it to even install. The documentation was severely lacking and there was no actual installer for OSX. I probably wouldn't have had a problem if I was more familiar with the differences between bash (what the instructions were written for) and zsh (what came preinstalled on my MacBook Pro), but I'm not and I couldn't figure out how to make it work correctly when the given bash instructions failed in zsh. However, in the meantime I've also become much more familiar with ways in which people make RDBMS work to solve problems like mine, and PostgreSQL installed easily and without trouble, so that's what I'm using. I am, however, keeping all the database interaction separate from the rest of the code, so if I change my mind later it will be simple to rewrite!